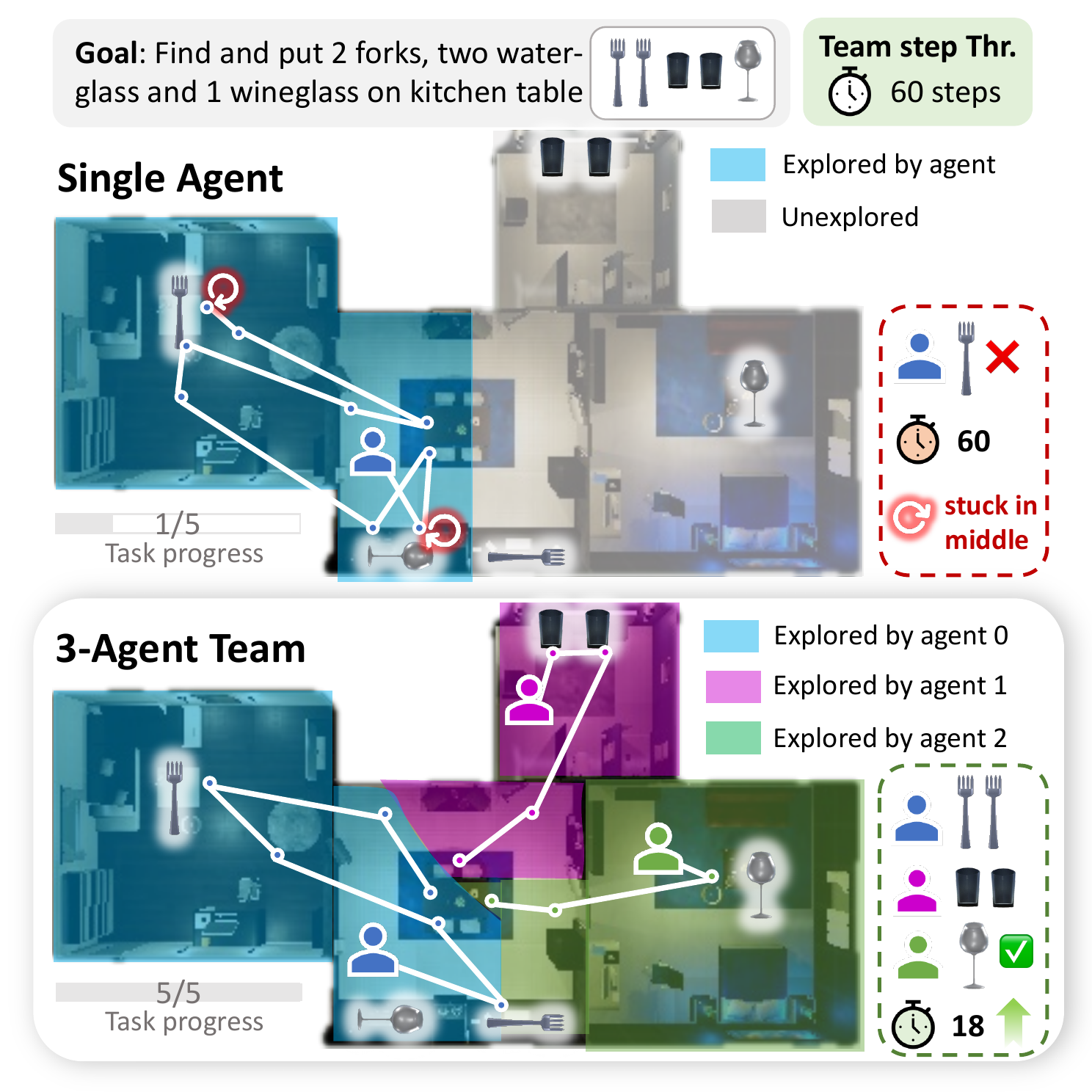
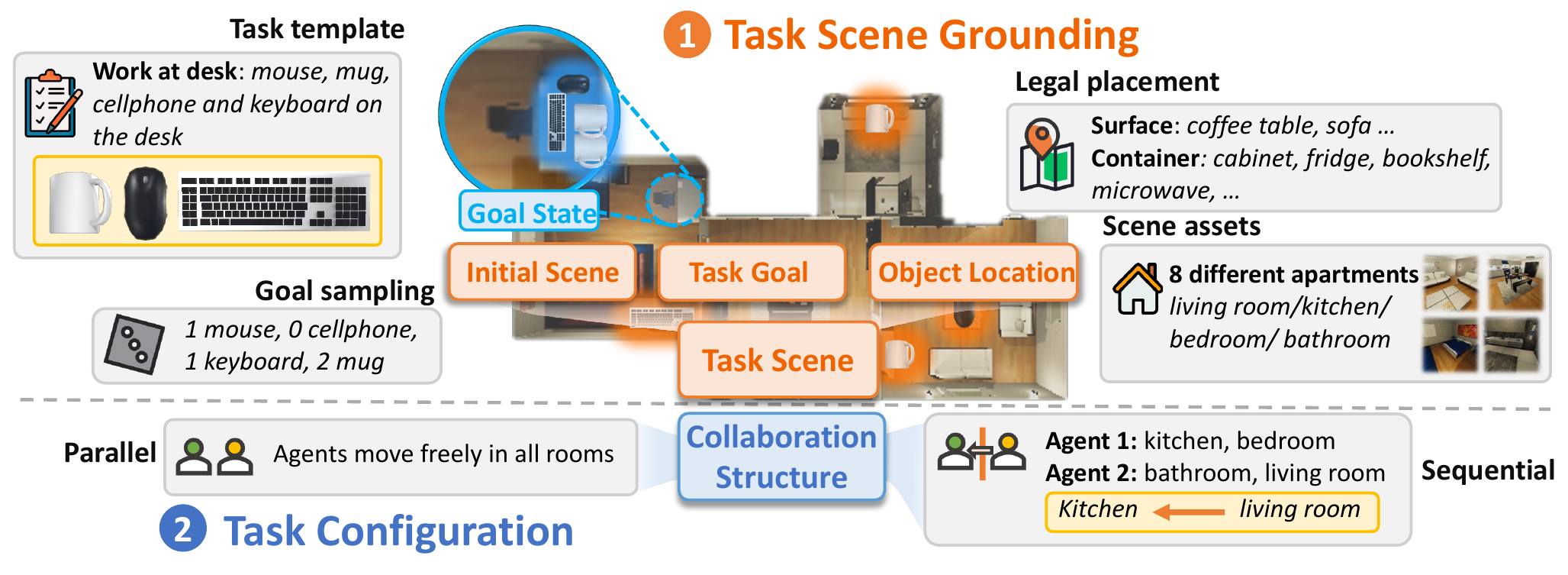
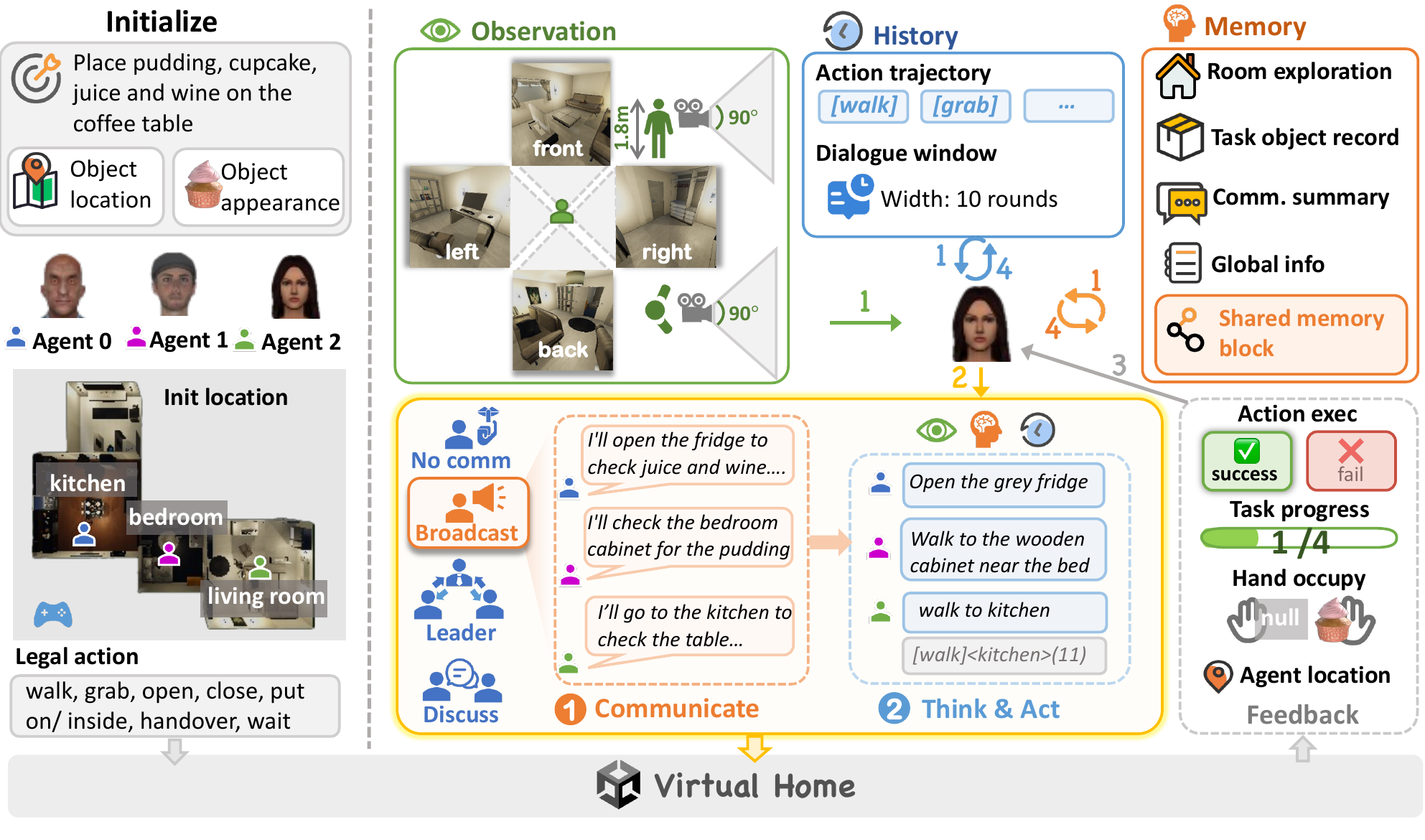
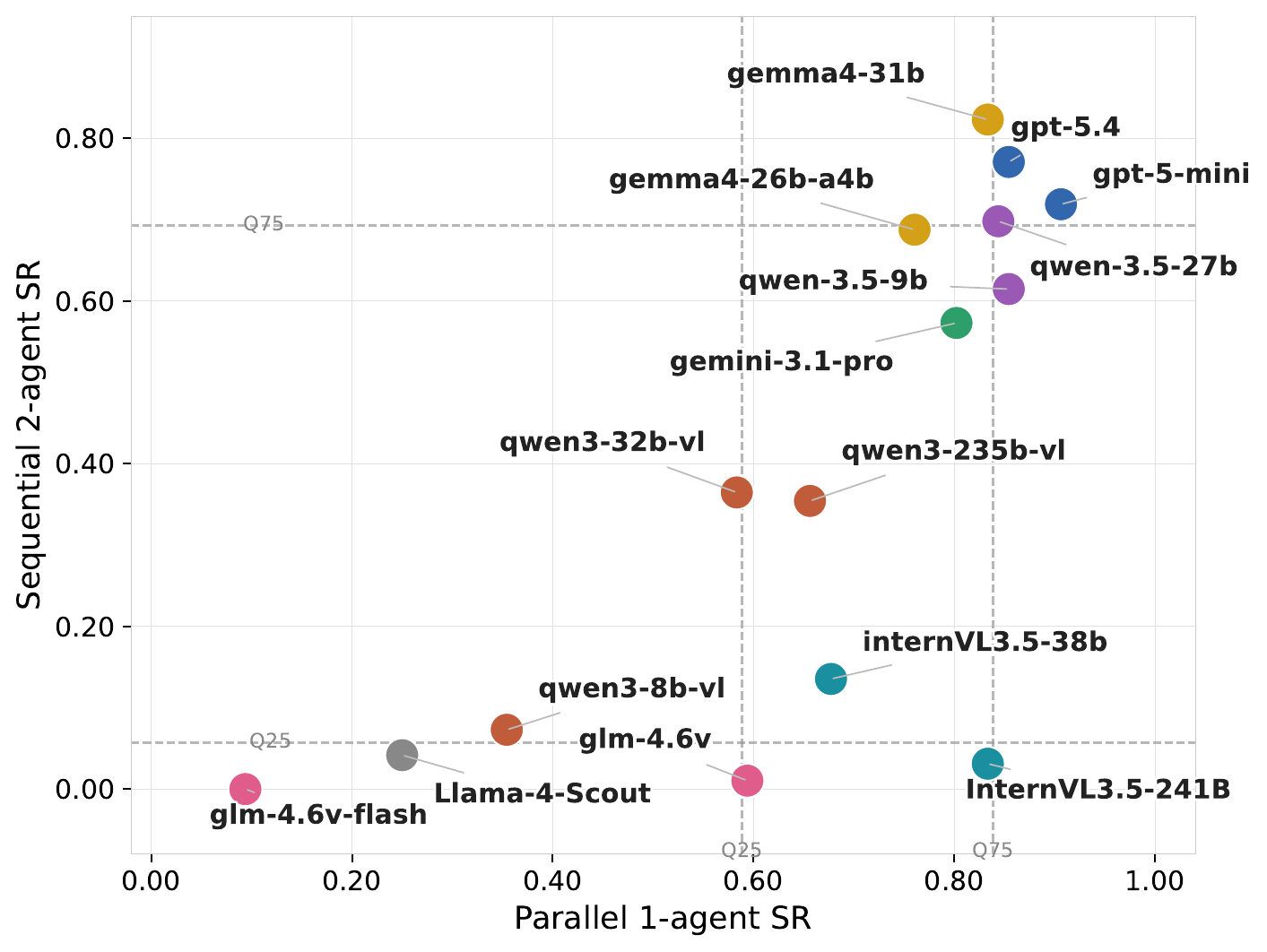
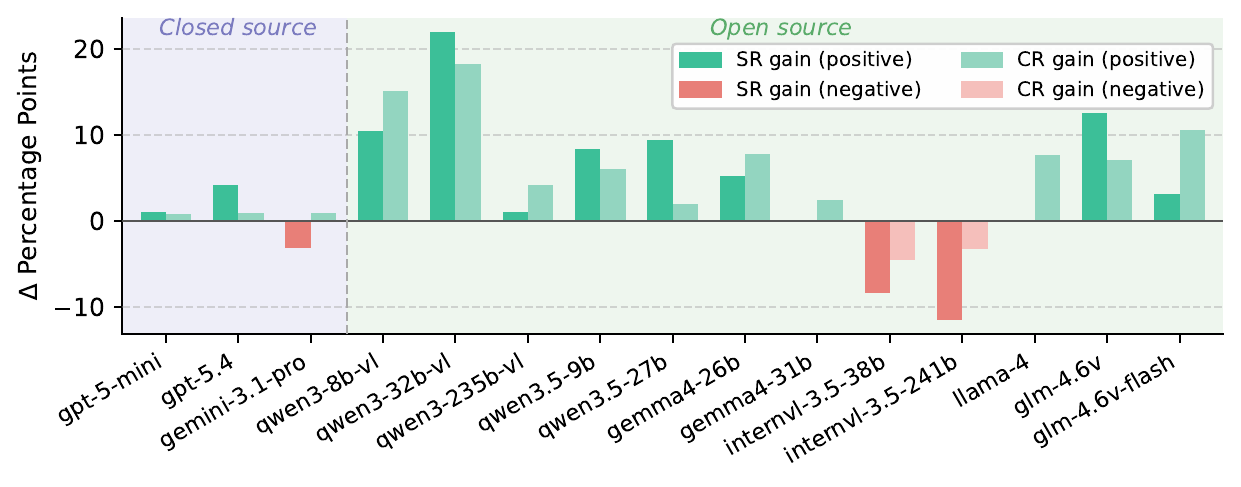
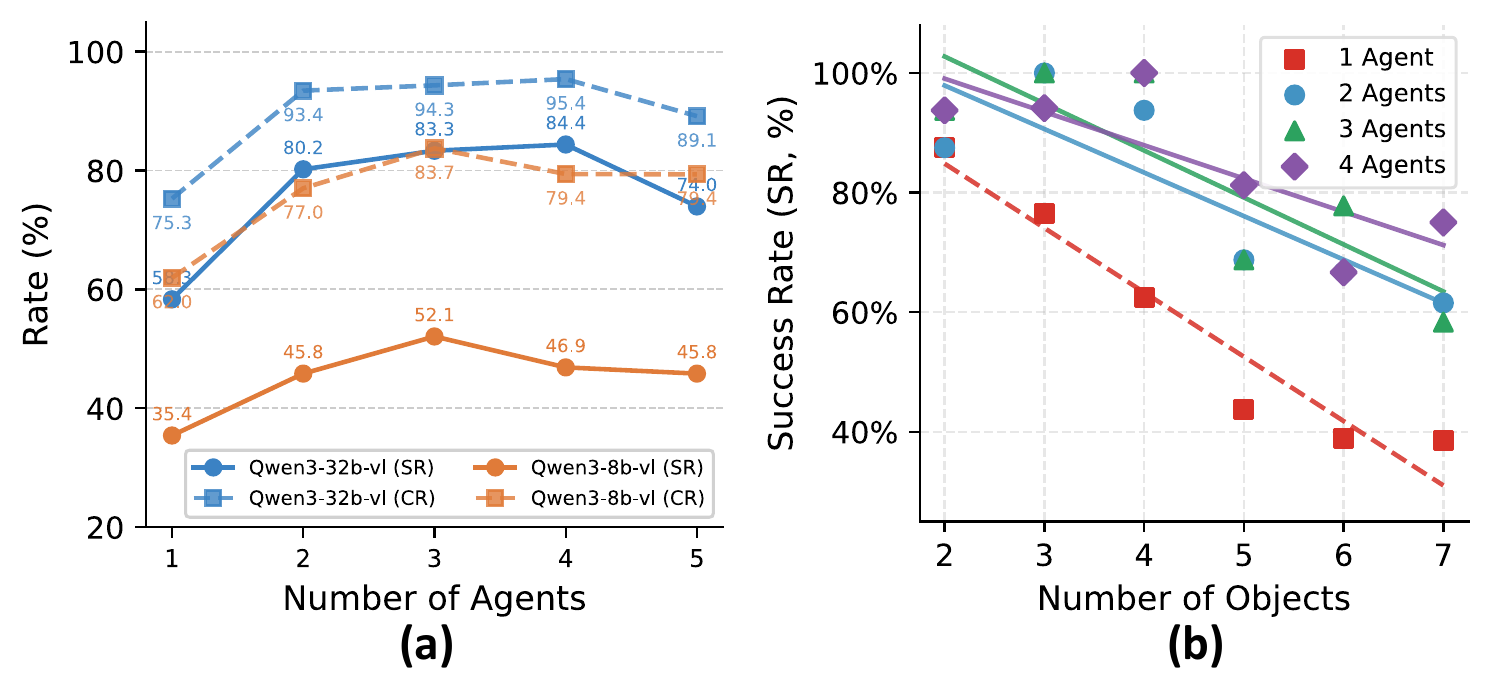
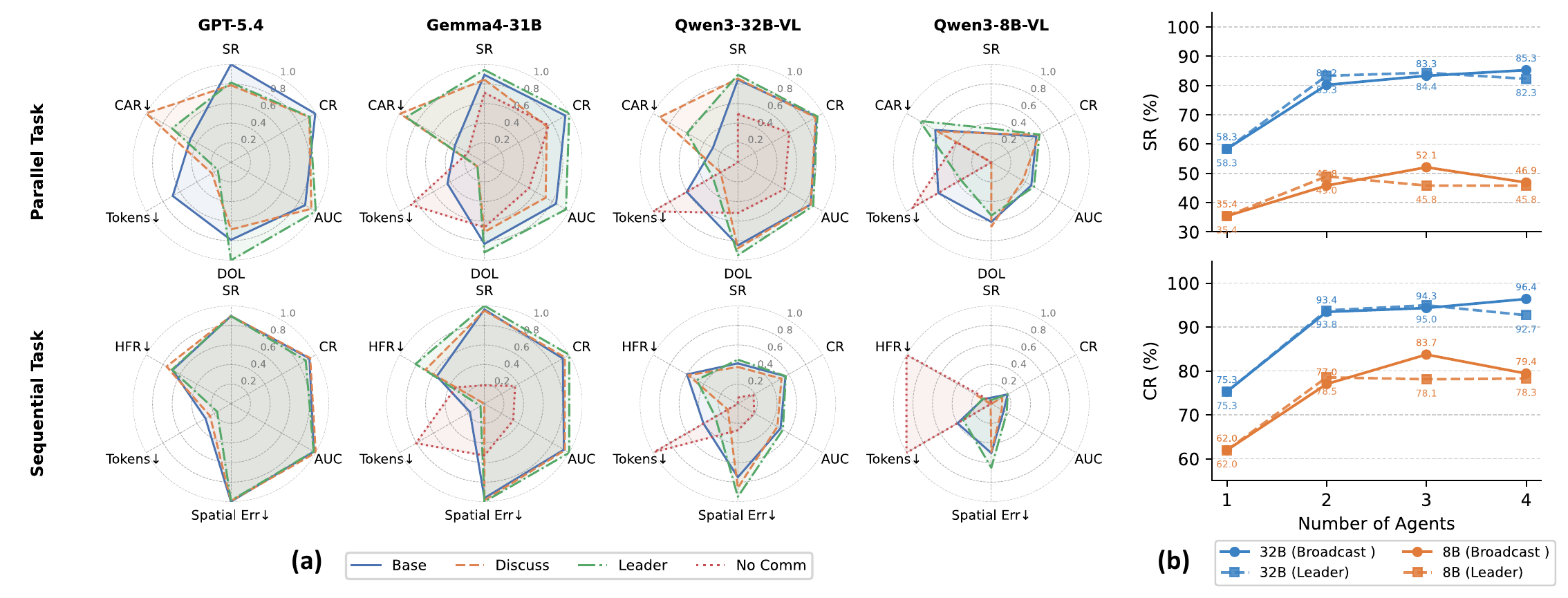
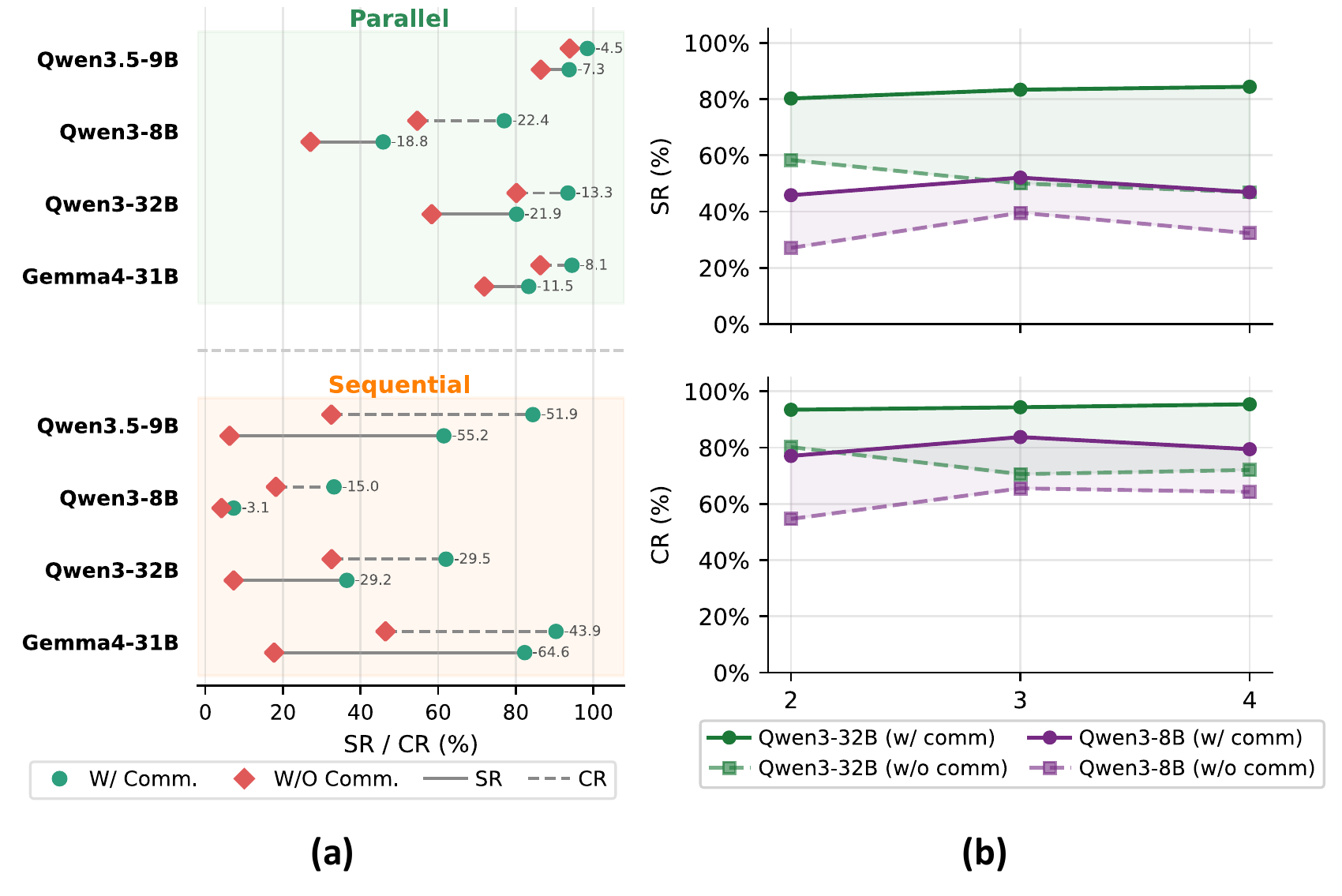
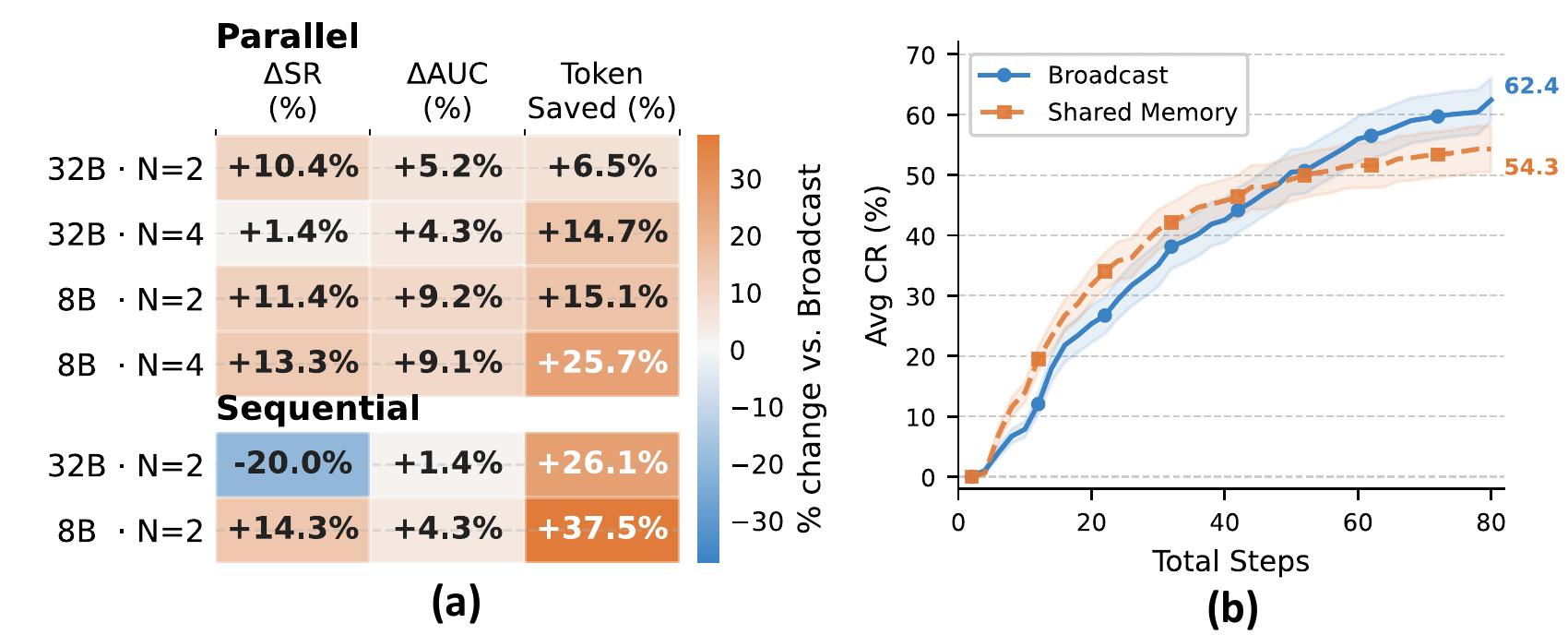
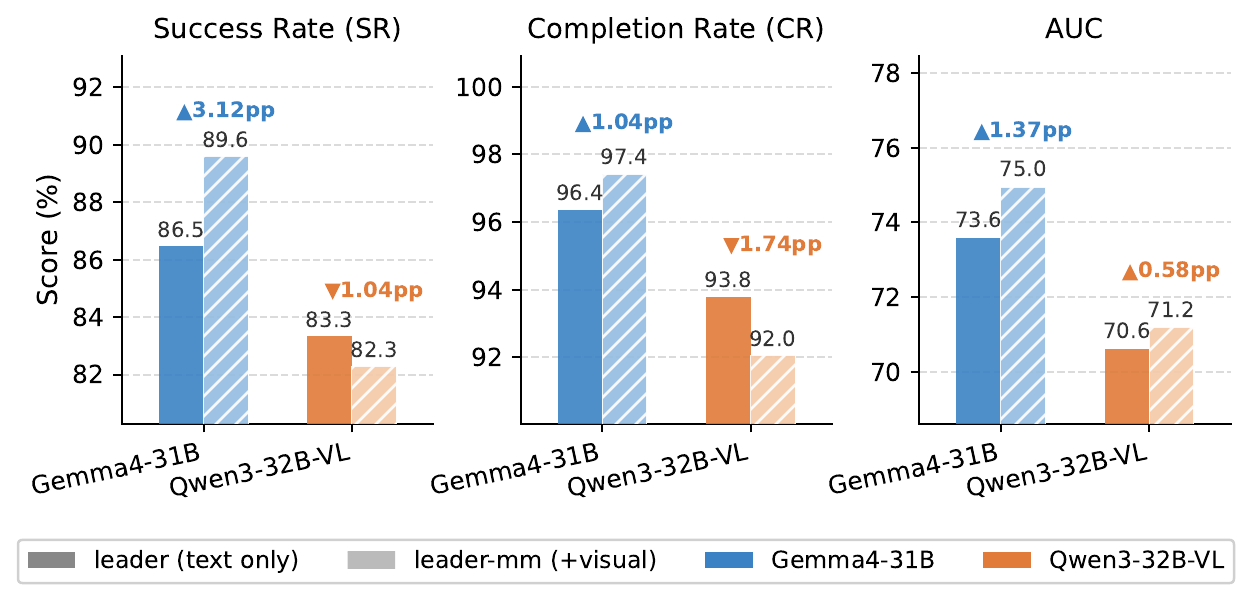
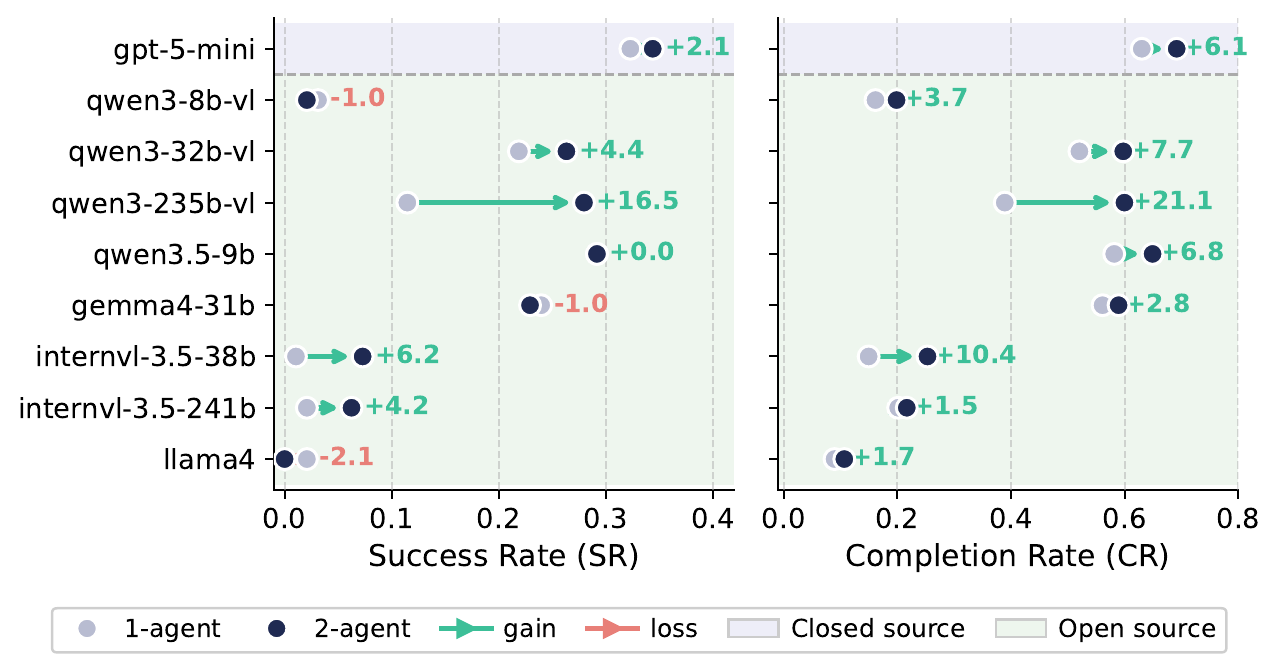
Recent multimodal large language models (MLLMs) have strong potential as embodied agents, but their ability to collaborate in visually grounded environments remains underexplored. To address this gap, we introduce MECoBench, a multimodal embodied cooperation benchmark with an evaluation platform spanning diverse real-world tasks, two cooperation structures, and three collaboration modes. Through extensive experiments across various MLLMs, we summarize three key findings: (i) Collaboration generally improves embodied task completion, but its benefits depend on balancing collaborative gains against coordination complexity. (ii) Communication is essential to collaboration gains, while the best collaboration mode depends on team size and model capability. (iii) Collaboration improves robustness under noisy priors and exploration conditions. Overall, MECoBench provides a systematic testbed for understanding the mechanisms and limits of multimodal embodied collaboration.